This article introduces how to setup the denpendicies and environment for using OCR technic to extract data from scanned PDF or image.
extracting normal pdf is easy and convinent, we can just use pdfminer and pdfminer.six (for python2 and python3 respectively) and follow the instruction to get text content. But for those scanned pdf, it is actually the image in essence. To extract the text from it, we need a little bit more complicated setup. In addition, it is easy for linux system but hard for windows system.
Basic package and software needed
We want to use pyocr to extract what we need. And in order to use if correctly, we need the following important denpendencies
- Python Imaging Library (PIL)
- Wand
- tesseract-ocr
- ghostscript
-
Note that PIL could use conda install pil. And also we need to setup the environment and path.
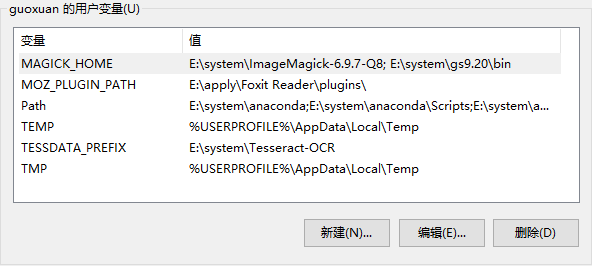
First of all, do not change the default name of the folder, you can change the directory. But if you change the directory, you need to change some path setup from tesseract.py.py in pyocr package.For the system path and environment, you need to add the directory of ghostscript, ImageMagick, tesseract-ocr into system path:
create a new name MAGICK_HOME and set ImageMagick,ghostscript as E:\system\ImageMagick-6.9.7-Q8; E:\system\gs9.20\bin
- add them into the path E:\system\ImageMagick-6.9.7-Q8; E:\system\gs9.20\bin
- create a new name TESSDATA_PREFIX and set tesseract directory E:\system\Tesseract-OCR
change the tesseract.py as
1
2
3
4
5
6# CHANGE THIS IF TESSERACT IS NOT IN YOUR PATH, OR IS NAMED DIFFERENTLY
TESSERACT_CMD = os.environ["TESSDATA_PREFIX"]+ os.sep +'tesseract.exe' if os.name == 'nt' else 'tesseract'
TESSDATA_EXTENSION = ".traineddata"
logger = logging.getLogger(__name__)
when you successfully setup, you can open the cmd, and input :convert filename.pdf filename.jpg
to see whether it can operate correctly.
python OCR stript
When all those are done. We are able to write the python script :
- importing the required libraries:
1 | from wand.image import Image |
- get the handle of the OCR library (tesseract)
1 | tool = pyocr.get_available_tools()[0] |
If your tesseract does not setup correctly, you will encount null value in this part, please carefully check the environment path setup.
- setup two lists to store the images and final_text
1 | req_image = [] |
- open the PDF file using wand and convert it to jpeg
1 | image_pdf = Image(filename="path/filename.pdf", resolution=300) |
If the ghostscript does not setup correctly, this part will raise the error, usually I encounter 798 : the system could not find the file. Here you need not only check the environment path but also do not change the folder’s name, because I change the folder’s name at the beginning, It tooks me a long time to fix this problem.
wand has converted all the separate pages in the PDF into separate image blobs. We can loop over them and append them as a blob into the req_image list.
1 | for img in image_jpeg.sequence: |
- run OCR to get the text
1 | for img in req_image: |
It will take a few minuite to finsih the converting.
Full code
The Full code is
1 | # -*- coding: utf-8 -*- |